About BenchGen
The Synthetic Data Factory
for AI Agents
BenchGen is a simulation and benchmarking platform for AI agents — a flight simulator that tests how agents perform in environments that reflect real operations. Instead of relying on static benchmarks, BenchGen runs agents inside simulated systems, replicating APIs, tools, and multi-step workflows to observe how they actually behave.
Mission
Enable organisations to build reliable, measurable, and continuously improving AI agents through synthetic data generation, automated evaluation, and training infrastructure.
The Problem
The demo-to-production gap
AI agents are rapidly being adopted across industries, but most implementations fail to deliver measurable business value. Agents perform well in controlled demos — then break in production. Less than 10% of enterprises achieve meaningful value from AI agent deployments, and reliable benchmarking remains the bottleneck.
Lab
Controlled demos, ideal conditions
Pilot
Limited scope, curated data
Production
Real users, real failures
Solution
An end-to-end improvement loop
BenchGen captures decisions, failures, and outcomes across full task trajectories — turning them into reliability metrics and training data. It doesn't just tell you what score your agent got; it shows you exactly where it failed and generates the data needed to fix it.
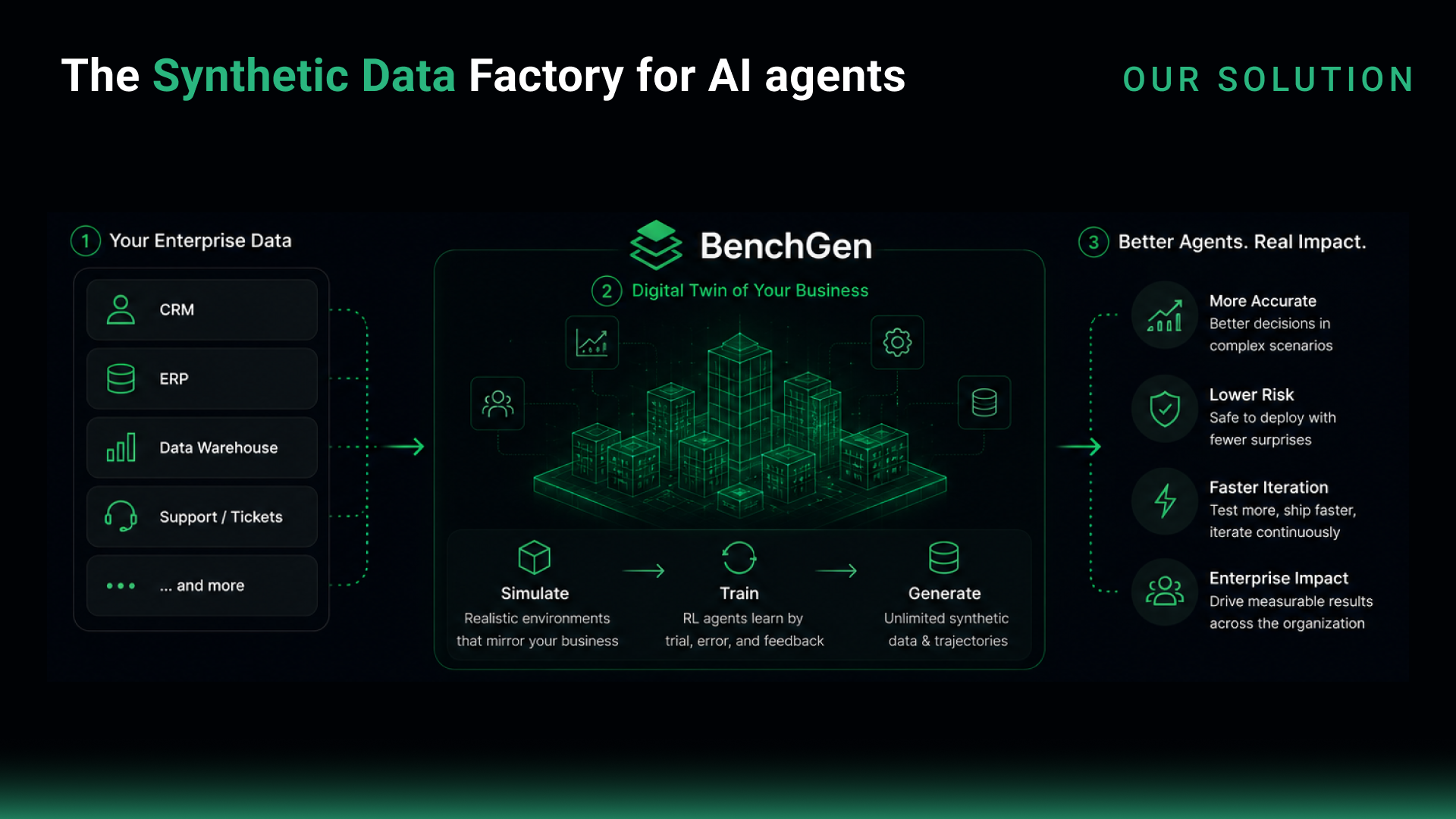
Synthetic Data Generation
- Customer interactions
- Business process workflows
- Edge cases & failure conditions
- Industry-specific scenarios
Agent Evaluation
- Task completion rates
- Accuracy & reliability
- Cost efficiency
- Response quality & consistency
Benchmarking
- Agent versions vs each other
- Model providers
- Prompt strategies
- Fine-tuned systems
Continuous Improvement
- Detect weaknesses automatically
- Generate new test cases
- Produce training datasets
- Improve future performance
Why BenchGen
Built for production-grade AI
Reliable AI Deployment
Validate AI agents inside realistic simulated environments before any production rollout — catch failures that controlled demos never surface.
Reduced Risk
Identify failure modes before they impact customers and operations. Every weakness is discovered in simulation, not in production.
Faster Iteration
Automatically generate evaluation datasets and improvement cycles. No manual test case writing — BenchGen creates the scenarios from your data.
Measurable Performance
Track agent improvements using consistent benchmarks and KPIs. Turn vague "it seems better" into verifiable, auditable metrics.
Enterprise Ready
Designed for organisations deploying AI at scale — sovereign, on-premise, air-gapped, and regulated environments supported.
Market Opportunity
A $28B infrastructure category
TAM
$28B
Total Addressable Market — agent infrastructure and evaluation platforms
SAM
$4.2B
Serviceable market — evaluation, simulation, and benchmarking solutions
SOM
$75M
Initial target — Europe, Türkiye, and GCC region
Team
Built by practitioners
Andrii Bidochko
Co-Founder
- PhD in AI Systems
- 90+ software projects delivered
- 13+ years in software products
- Published research on long-horizon LLM agents in Elsevier's Journal of Computational Science
Tolga Dincer
Co-Founder
- Lifelong technologist
- Specialist in AI-native cloud architecture
- Focused on digital sovereignty
- Experience across fintech, defense, and public-sector infrastructure
Ruslan Synytsky
Co-Founder
- Serial entrepreneur & Java Champion
- Founder of Jelastic PaaS
- Scaled infrastructure across 100+ data centers
- Acquired by Virtuozzo in 2021
- Advisor on infrastructure strategy and cloud partnerships
Get started
Every AI agent should be tested before it ships
BenchGen transforms AI development from trial-and-error experimentation into a measurable engineering discipline. Start with the free Skill Checker or join the waitlist for the full platform.