Two actions after training
When a run completes, the Actions panel offers two things:| Action | Result |
|---|---|
| Download Adapter (.zip) | The raw LoRA adapter on its own. Use this if you want to keep or apply the adapter yourself. |
| Merge Model | Combines the adapter with the base model into a full checkpoint you can save, run, and evaluate. |
You don’t have to merge just to test the model. Train can run inference against the adapter directly. See Run inference.
Steps
1. Open the completed run
Go to Train → Jobs and open the completed job. The Actions panel reads “Model ready — select an action below”.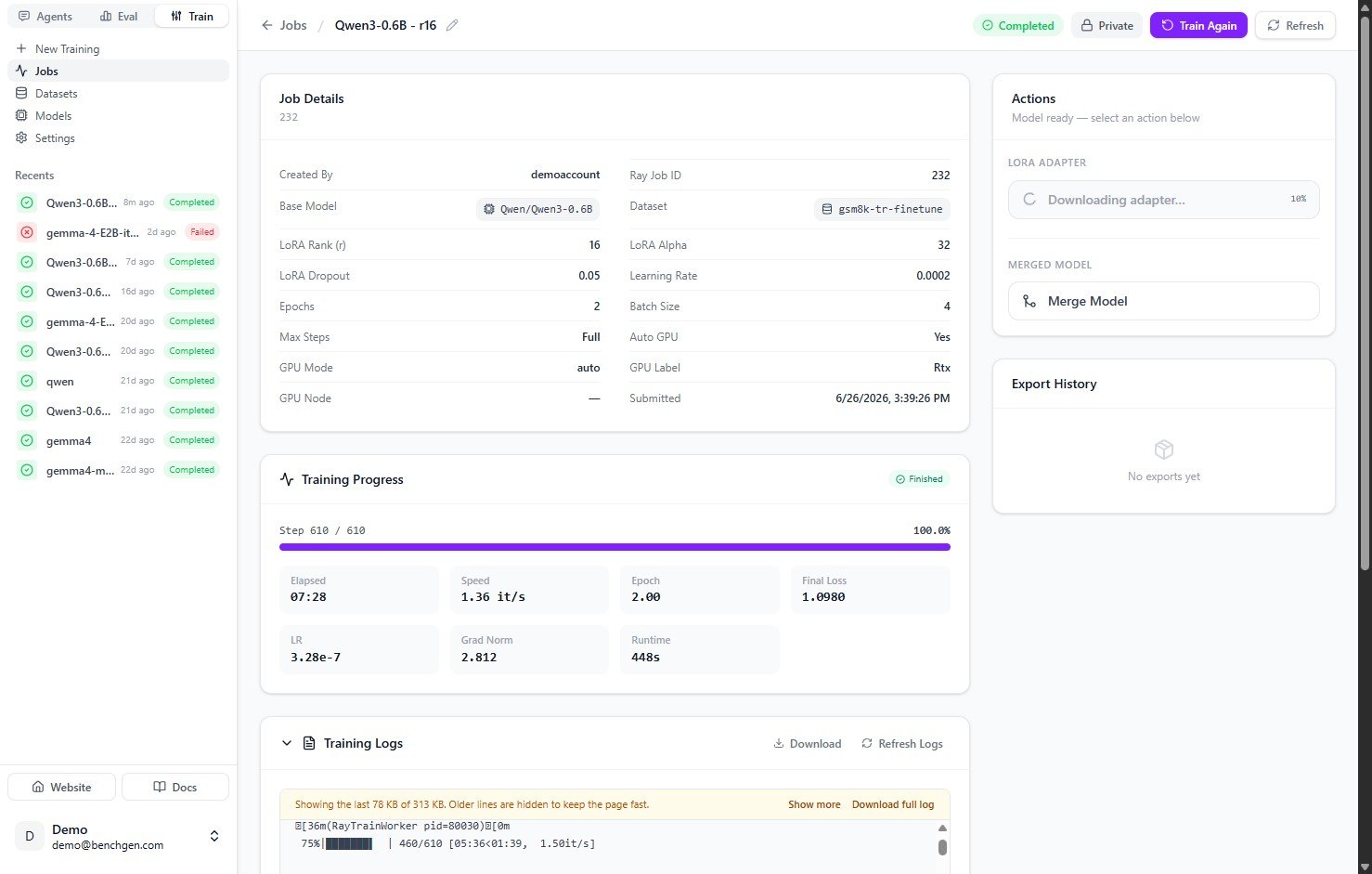
2. Merge the adapter
Under Merged Model, click Merge Model. Merging starts, the panel shows “Merging in progress…”, and a new entry appears in Export History with a Preparing badge. This usually takes a couple of minutes.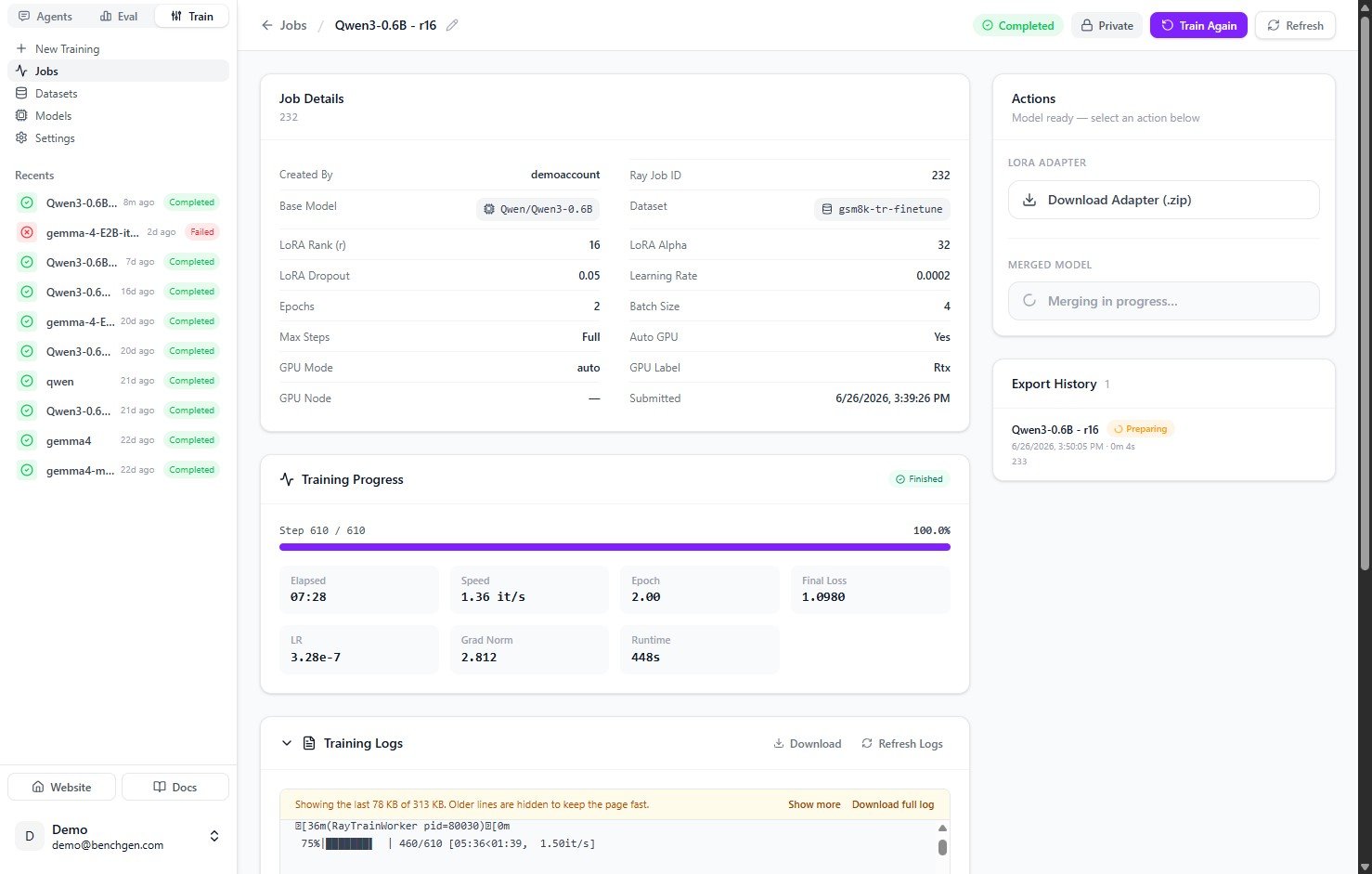
3. Name the model
When the merge is ready, click Save on Platform on the Export History entry. In the Name this model on BenchGen dialog, enter the name the model will appear under (for exampleQwen3-0.6B_math), then click Push to BenchGen.
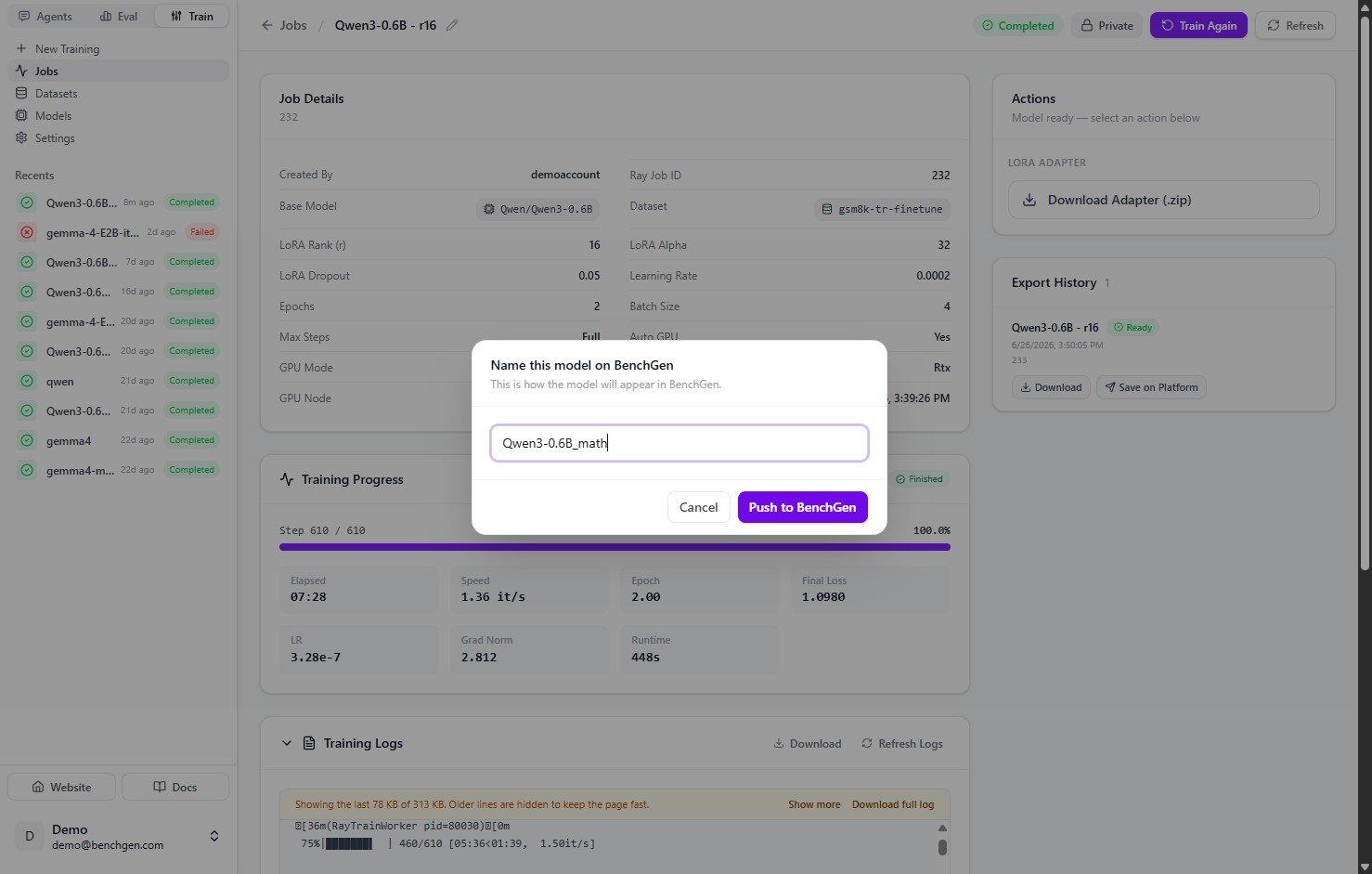
4. Confirm it’s saved
The Export History entry updates to Ready and Pushed, with a Saved on Platform check. You can also Download the merged checkpoint from here.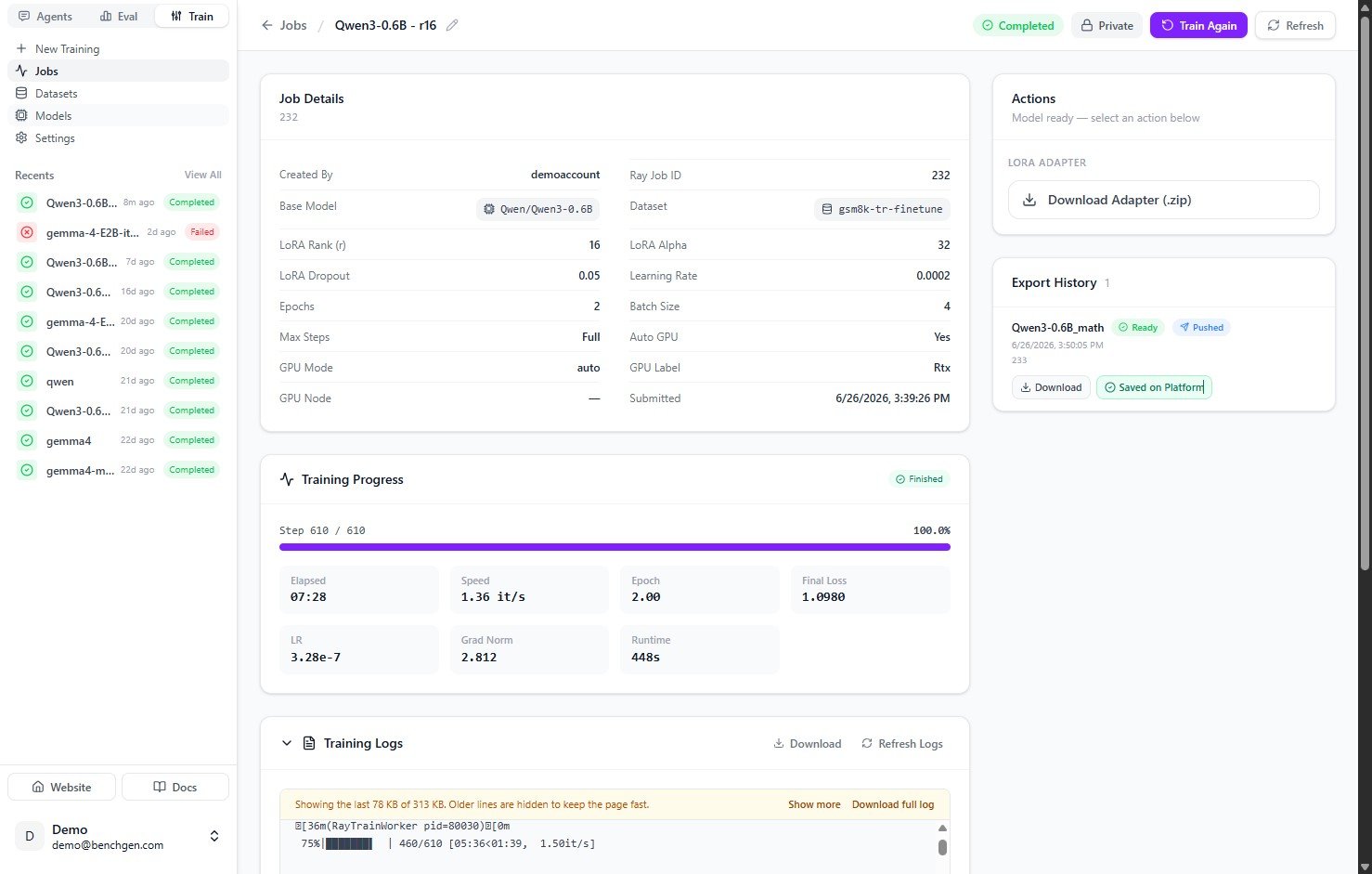
5. Use the model
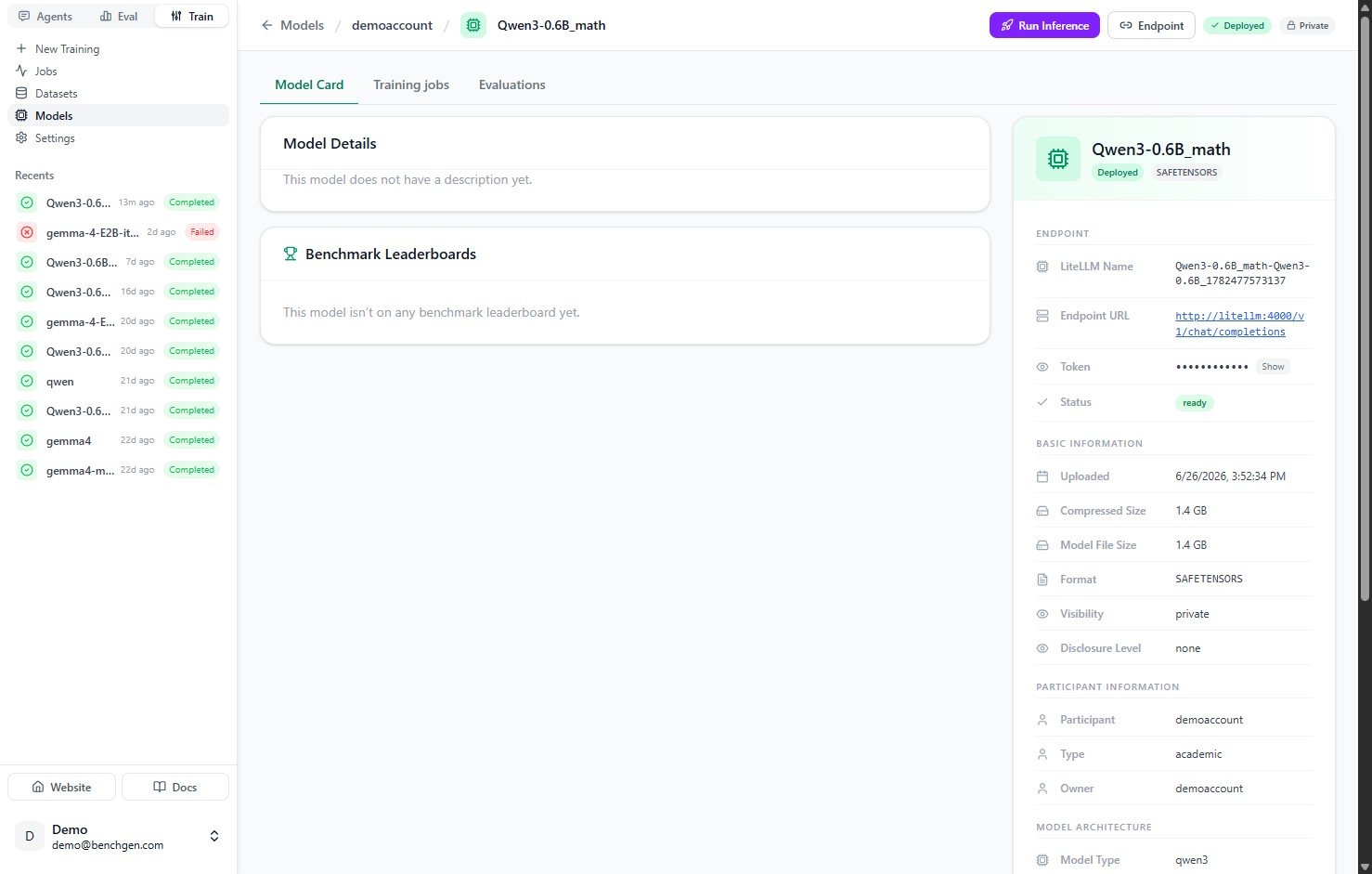
The saved model now appears in Models as a deployed, ready endpoint. Open it to Run Inference or evaluate it. Its endpoint panel shows the LiteLLM Name, Endpoint URL, access Token, and aSAFETENSORS format.
Next Steps
Your model is saved on BenchGen and ready to use. Head over to Eval to serve it as a live endpoint, then benchmark it against an environment.
Deploy an inference model
Spin up a live, OpenAI-compatible endpoint for your saved model.
Evaluate an inference model
Benchmark the running model against an environment and read the scores.