Prerequisites
- A saved model from a training run (see Merge & save a model), or any model in your workspace (see Add a model).
- A GPU node with free capacity.
Steps
1. Open the model and click Run Inference
Open the model’s card and click Run Inference in the top right.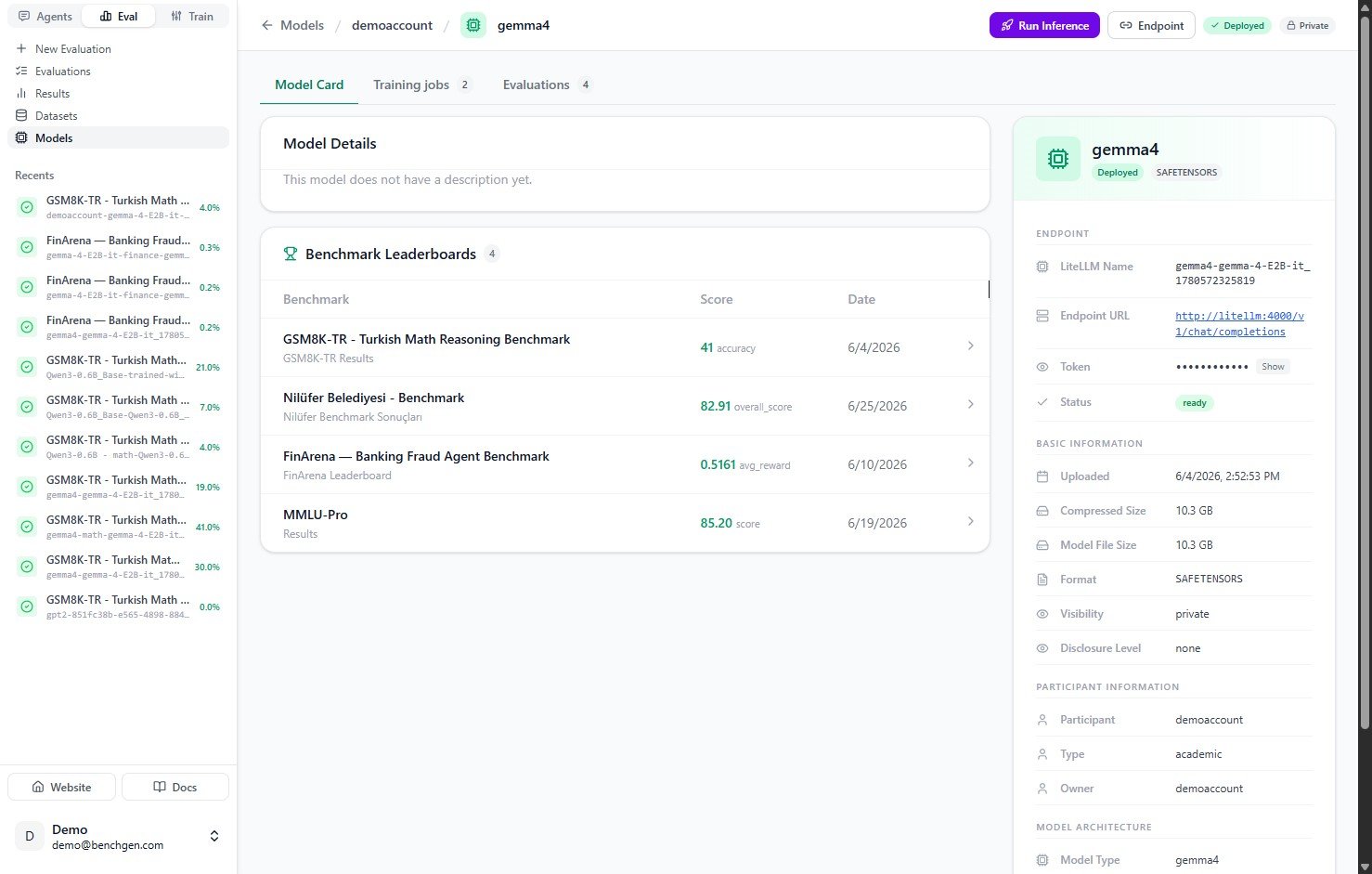
2. Configure and start
In the Run Inference dialog, pick a GPU and review the inference settings (max tokens, temperature, top P, context length, precision), then click Run model.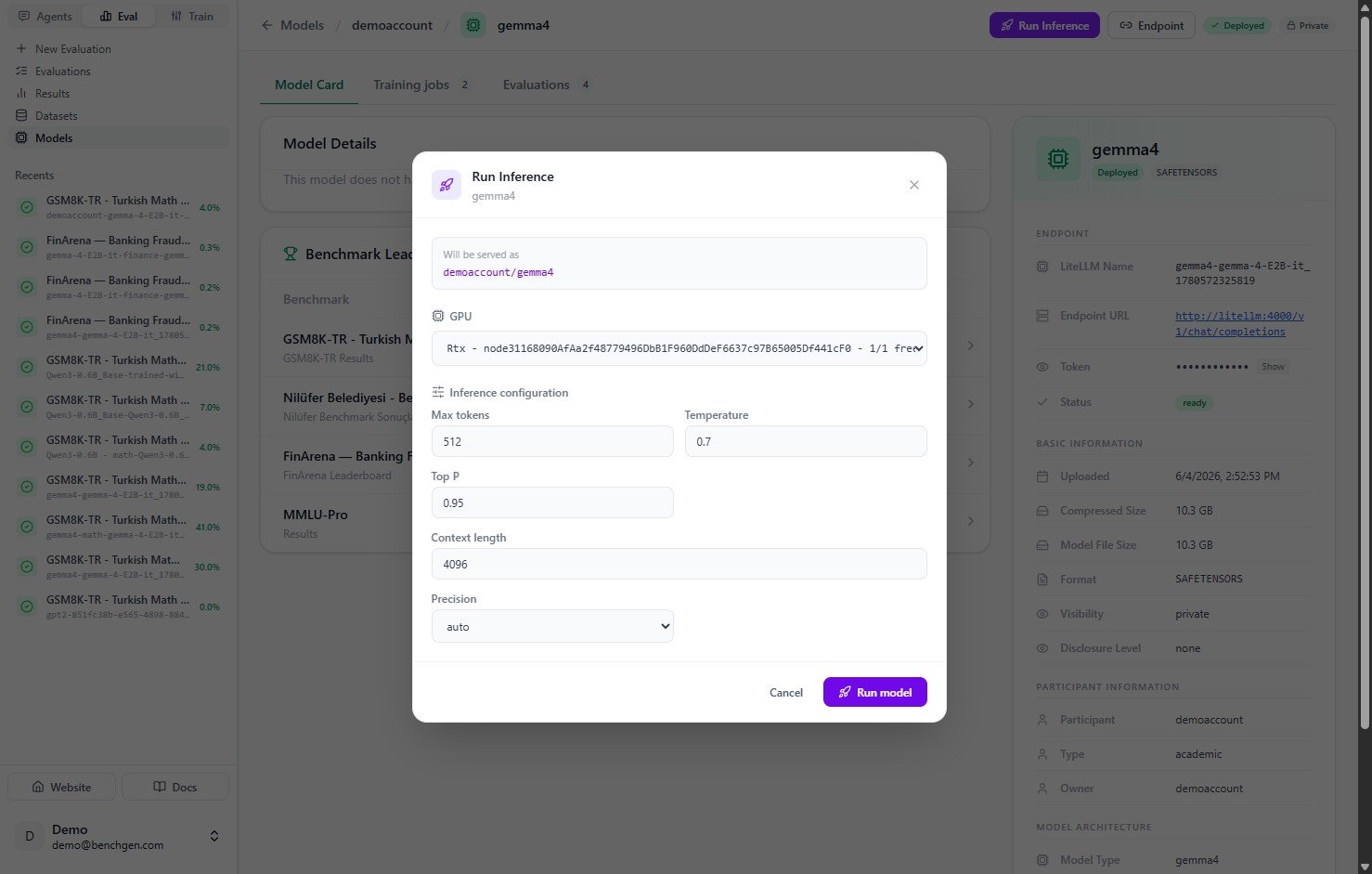
3. Wait for the endpoint to be ready
The status reads Deploying while the model starts up, then turns to running once it’s live. The model card’s endpoint panel fills in with the LiteLLM Name, Endpoint URL, and access token.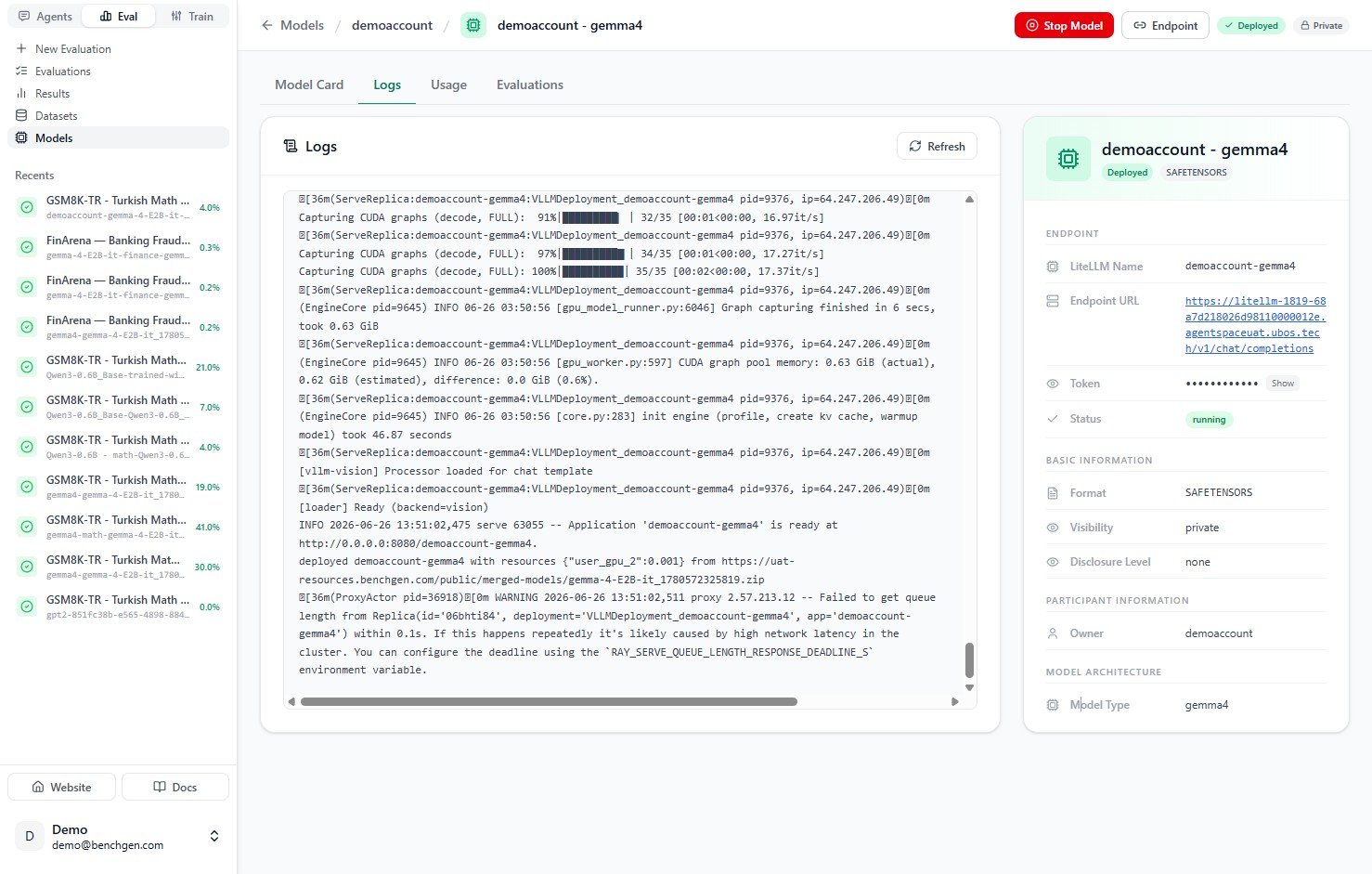
Send requests
Once the status is running, the endpoint is OpenAI-compatible. Use the LiteLLM Name, Endpoint URL, and Token from the model card:Next Steps
- Monitor model usage to track requests, tokens, and latency.
- Evaluate an inference model to benchmark it against an environment.
- Run a benchmark to measure improvement formally.